Cauchy Statistics
I was attempting to restore some sort of order to my office today when I stumbled across some old jottings about the Cauchy distribution, which is perhaps more familiar to astronomers as the Lorentz distribution. I never used in the publication they related to so I thought I’d just quickly pop the main idea on here in the hope that some amongst you might find it interesting and/or amusing.
What sparked this off is that the simplest cosmological models (including the particular one we now call the standard model) assume that the primordial density fluctuations we see imprinted in the pattern of temperature fluctuations in the cosmic microwave background and which we think gave rise to the large-scale structure of the Universe through the action of gravitational instability, were distributed according to Gaussian statistics (as predicted by the simplest versions of the inflationary universe theory). Departures from Gaussianity would therefore, if found, yield important clues about physics beyond the standard model.
Cosmology isn’t the only place where Gaussian (normal) statistics apply. In fact they arise generically, in circumstances where variation results from the linear superposition of independent influences, by virtue of the Central Limit Theorem. Noise in experimental detectors is often treated as following Gaussian statistics, for example.
The Gaussian distribution has some nice properties that make it possible to place meaningful bounds on the statistical accuracy of measurements made in the presence of Gaussian fluctuations. For example, we all know that the margin of error of the determination of the mean value of a quantity from a sample of size 

However, although the Gaussian assumption often applies it doesn’t always apply, so if we want to think about non-Gaussian effects we have to think also about how well we can do statistical inference if we don’t have Gaussianity to rely on.
That’s why I was playing around with the peculiarities of the Cauchy distribution. This comes up in a variety of real physics problems so it isn’t an artificially pathological case. Imagine you have two independent variables 

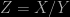

which is a form of the Cauchy distribution. There’s nothing at all wrong with this as a distribution – it’s not singular anywhere and integrates to unity as a pdf should. However, it does have a peculiar property that none of its moments is finite, not even the mean value!
Following on from this property is the fact that Cauchy-distributed quantities violate the Central Limit Theorem. If we take 
The Cauchy distribution has infinite variance so the distribution of the sum of independent Cauchy-distributed quantities 
This was essentially the point I made in a previous post about the dangers of using standard statistical techniques – which usually involve the Gaussian assumption – to distributions of quantities formed as ratios.
We cosmologists should be grateful that we don’t seem to live in a Universe whose fluctuations are governed by Cauchy, rather than (nearly) Gaussian, statistics. Measuring more of the Universe wouldn’t be any use in determining its global properties as we’d always be dominated by cosmic variance..

June 8, 2010 at 11:17 pm
I really think this, and Peter’s interaction with the biologists, should required reading for physics students!!
I still worry that many astronomers are leaving their PhDs with too basic a level of statistics and reasoning, and stories like this will help them realise its importance.
June 9, 2010 at 2:47 pm
Does space roar prove that the standard cosmological model has serious problems? According to the ideas of Fredkin and Wolfram, the maximum physical wavelength is the Planck length times the Fredkin-Wolfram constant. This hypothesis when added to M-theory creates what one might call “finitary, digital M-theory” — and seems to explain the space roar. The space roar experimentalists found 6 times as much electromagnetic noise from the early universe than the standard model of cosmology seems to predict. Is the explanation of the space roar the key to re-writing the logical foundations of physics?
June 9, 2010 at 2:59 pm
Mathematically this is spot-on, but if X and Y have very differing width then it is wise to consider how the Cauchy form emerges from the integration that gives the distribution for their ratio. Too much contribution from outlying regions and you might want to look more closely at your prior information, and at your arguments why X and Y are Gaussian.
June 9, 2010 at 3:44 pm
Anton: I should have made the point that many things are close to Gaussian, but they’re not exactly so (especially if they’re positive definite). Sometimes the tail behaviour deviates from Gaussianity, however, which means the ratio variable is not Cauchy.
Phillip: I think “Space Roar” is what I blogged about here:
https://telescoper.wordpress.com/2009/01/18/whats-all-the-noise/
As far as I know it’s still unexplained, but it could at least in principle be explained by galaxies rather than requiring more esoteric theories.
June 10, 2010 at 10:36 am
This might be an appropriate post to let readers know that, after more than 40 years, a major update of the workhorse reference book of mathematical functions by Abramowitz and Stegun has just been published. It is now called the NIST Handbook of Mathematical Functions, eds Olver et al, pubs Cambridge University Press. My pre-ordered copy from Amazon came yesterday and it is the biz. It will be a bit of a wrench to give away my old edition as we have been through a lot together, but such is progress.
Anton
June 10, 2010 at 1:35 pm
Is the mean of the Cauchy distribution zero or infinite…?
Its entropy, which might be a more meaningful measure of the width of a distribution than the standard deviation, is finite, although \int dz p(z) log p(z) (over all z) is a meaty integral to calculate for the Cauchy form.
June 10, 2010 at 1:42 pm
The mean must be zero by symmetry but the contributions arising from either side of zero are infinite. In other words the mean of mod(z) is infinite…
I think the entropy may be divergent too, but I’ve never really looked at it. Interesting.
June 10, 2010 at 1:51 pm
Its entropy is definitely convergent – the integrand behaves like (ln z)/(z^2) at large z, which is OK. This led me to waste an hour calculating it. I get
[sqrt(pi) – 1][ln2 + g/2] + ln\pi
where g stands for Euler’s constant. That’s a nice mix of transcendentals.
June 10, 2010 at 6:07 pm
Interesting. here’s a silly question. The Gaussian is the maximum entropy distribution for fixed mean and variance, right?
Assuming zero mean there would therefore seem to be a Gaussian distribution with variance adjusted so that it has the same entropy as a given Cauchy distribution (allowing forms like a^2 + z^2 instead of 1+z^2 in the denominator). What’s the relationship between the parameters of the Cauchy and the Gaussian that is “isentropic” to it, and what does this mean?
June 10, 2010 at 6:26 pm
Suppose for simplicity that the means of the distributions are zero. The Gaussian is constructed such that, of all distributions with identical variance, it alone has the greatest entropy. The entropy – variance relation is monotonic for the Gaussian,, so that this statement can be rephrased as: for identical entropies, the Gaussian has lower variance, ie the variance of others is greater.
And this is exactly what you find, because the variance of the Cauchy distribution is… infinity!
Anton
June 10, 2010 at 8:07 pm
Anton,
I didn’t make my question clear. Sure the variance of the Cauchy is infinite but it can be constructed in such a way that it has a parameter describing its width (i.e. replace z by z/a where a is a scale parameter). Now the variance will always be infinite but the shape of the distribution and consequently the entropy will depend on a.
For a given a and the entropy associated with it for a Cauchy distribution, one can find a Gaussian distribution with variance chosen to give the same entropy as a Cauchy distribution with any particular a. This requirement would give an equation between a and sigma for the two distributions to have the same entropy.
Do you get my point?
Peter
June 10, 2010 at 11:35 pm
Peter: Yes, you can set up the requirement that
S_{Cauchy}(a) = S_{Gaussian}(\sigma)
which is indeed an equation relating ‘a’ of the Cauchy distribution with \sigma of the Gaussian distribution. Are you saying that this leads somewhere…?
Anton
June 10, 2010 at 11:59 pm
No, I’m not saying it leads anywhere. I’m just wondering what it means. There’s a question behind this which I’ve been thinking about for some time, but I’ll have to think about it a lot more before I can articulate it!
June 11, 2010 at 9:42 am
Peter: LHS of the eqn in my last posting is just
ln(a) + S_{Cauchy}(a=1)
and RHS is
ln(sigma) + S_{Gaussian}(sigma=1)
so that the eqn simply means that ‘a’ and \sigma are in a fixed ratio (whose value involves pi, e, Euler’s const etc).
Anton