The Laws of Extremely Improbable Things
After a couple of boozy nights in Copenhagen during the workshop which has just finished, I thought I’d take things easy this evening and make use of the free internet connection in my hotel to post a short item about something I talked about at the workshop here.
Actually I’ve been meaning to mention a nice bit of statistical theory called Extreme Value Theory on here for some time, because not so many people seem to be aware of it, but somehow I never got around to writing about it. People generally assume that statistical analysis of data revolves around “typical” quantities, such as averages or root-mean-square fluctuations (i.e. “standard” deviations). Sometimes, however, it’s not the typical points that are interesting, but those that appear to be drawn from the extreme tails of a probability distribution. This is particularly the case in planning for floods and other natural disasters, but this field also finds a number of interesting applications in astrophysics and cosmology. What should be the mass of the most massive cluster in my galaxy survey? How bright the brightest galaxy? How hot the hottest hotspot in the distribution of temperature fluctuations on the cosmic microwave background sky? And how cold the coldest? Sometimes just one anomalous event can be enormously useful in testing a theory.
I’m not going to go into the theory in any great depth here. Instead I’ll just give you a simple idea of how things work. First imagine you have a set of 


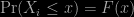
Now suppose you locate the largest value in the sample, 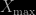

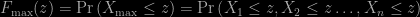
Because the variables are independent and identically distributed, this means that
![F_{\rm max} (z) = \left[ F(z) \right]^n](https://s0.wp.com/latex.php?latex=F_%7B%5Crm+max%7D+%28z%29+%3D+%5Cleft%5B+F%28z%29+%5Cright%5D%5En&bg=000000&fg=B0B0B0&s=0&c=20201002)
The probability density function associated with this is then just
![f_{\rm max}(z) = n f(z) \left[ F(z) \right]^{n-1}](https://s0.wp.com/latex.php?latex=f_%7B%5Crm+max%7D%28z%29+%3D+n+f%28z%29+%5Cleft%5B+F%28z%29+%5Cright%5D%5E%7Bn-1%7D&bg=000000&fg=B0B0B0&s=0&c=20201002)
In a situation in which
The mathematical interest in extreme values however derives from a paper in 1928 by Fisher \& Tippett which paved the way towards a general theory of extreme value distributions. I don’t want to go too much into details about that, but I will give a flavour by mentioning a historically important, perhaps surprising, and in any case rather illuminating example.
It turns out that for any distribution
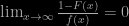
then there is a stable asymptotic distribution of extreme values, as 

where 


This result, and others, has established a robust and powerful framework for modelling extreme events. One of course has to be particularly careful if the variables involved are not independent (e.g. part of correlated sequences) or if there are not identically distributed (e.g. if the distribution is changing with time). One also has to be aware of the possibility that an extreme data point may simply be some sort of glitch (e.g. a cosmic ray hit on a pixel, to give an astronomical example). It should also be mentioned that the asymptotic theory is what it says on the tin – asymptotic. Some distributions of exponential type converge extremely slowly to the asymptotic form. A notable example is the Gaussian, which converges at the pathetically slow rate of 
The pitfalls are dangerous and have no doubt led to numerous misapplications of this theory, but, done properly, it’s an approach that has enormous potential.
I’ve been interested in this branch of statistical theory for a long time, since I was introduced to it while I was a graduate student by a classic paper written by my supervisor. In fact I myself contributed to the classic old literature on this topic myself, with a paper on extreme temperature fluctuations in the cosmic microwave background way back in 1988..

Of course there weren’t any CMB maps back in 1988, and if I had thought more about it at the time I should have realised that since this was all done using Gaussian statistics, there was a 50% chance that the most interesting feature would actually be a negative rather than positive fluctuation. It turns out that twenty-odd years on, people are actually discussing an anomalous cold spot in the data from WMAP, proving that Murphy’s law applies to extreme events…
Follow @telescoper
June 11, 2011 at 10:30 am
A likely story!
June 11, 2011 at 5:49 pm
I was slightly disappointed to read that Tippett (of Fisher & Tippett) wasn’t interested in earthquakes or tsunami or anything exciting like that when he worked on extreme value statistics. In fact he was working for a textile company making cotton goods, which failed when the weakest thread broke…
June 12, 2011 at 12:24 am
Very interesting topic – you can imagine that in collider experiments we would be interested in “extreme” events, too. People in particle physics sometimes talk about “rarity” as follows: suppose you observe an unusual event which might come from some standard model process but is unlikely it some of its features. How likely is it that an event that “rare” is found, assuming that no non-standard model processes are at work? This can be quantified by integrating an appropriate probability distribution function (often just a squared matrix element) in a clever way. Based on this post, though, I suspect that “rarity” was invented long ago and we particle types are just ignorant of it… ;)
Michael
November 12, 2011 at 1:33 pm
[…] theory. In the paper we approach the issue in a different manner to other analyses and apply Extreme Value Statistics to ask how massive we would expect the largest cluster in the observable universe should be as a […]
August 23, 2022 at 4:15 pm
[…] Once upon a time (over a decade ago when I was still in Cardiff), I wrote a paper with PhD student Ian Harrison on the biggest (most massive) galaxy clusters. I even wrote a blog post about it. It was based on an interesting branch of statistical theory called extreme value statistics which I posted about in general terms here. […]