I thought I’d post a quick follow-up to last week’s item about the Research Excellence Framework (REF). You will recall that in that post I expressed serious doubts about the ability of the REF panel members to carry out a reliable assessment of the “ouputs” being submitted to this exercise, primarily because of the scale of the task in front of them. Each will have to read hundreds of papers, many of them far outside their own area of expertise. In the hope that it’s not too late to influence their approach, I thought I’d offer a few concrete suggestions as to how things might be improved. Most of my comments refer specifically to the Physics panel, but I have a feeling the themes I’ve addressed may apply in other disciplines.
The first area of concern relates to citations, which we are told will be used during the assesment, although we’re not told precisely how this will be done. I’ve spent a few hours over the last few days looking at the accuracy and reliability various bibliometric databases and have come to the firm conclusion that Google Scholar is by far the best, certainly better than SCOPUS or Web of Knowledge. It’s also completely free. NASA/ADS is also free, and good for astronomy, but probably less complete for the rest of physics. I therefore urge the panel to ditch its commitment to use SCOPUS and adopt Google Scholar instead.
But choosing a sensible database is only part of the solution. Can citations be used sensibly at all for recently published papers? REF submissions must have been published no earlier than 2008 and the deadline is in 2013, so the longest time any paper can have had to garner citations will be five years. I think that’s OK for papers published early in the REF window, but obviously citations for those published in 2012 or 2013 won’t be as numerous.
However, the good thing about Google Scholar (and ADS) is that they include citations from the arXiv as well as from papers already published. Important papers get cited pretty much as soon as they appear on the arXiv, so including these citations will improve the process. That’s another strong argument for using Google Scholar.
The big problem with citation information is that citation rates vary significantly from field to field sit will be very difficult to use bibliometric data in a formulaic sense, but frankly it’s the only way the panel has to assess papers that lie far from their own expertise. Unless anyone else has a suggestion?
I suspect that what some panel members will do is to look beyond the four publications to guide their assessment. They might, for example, be tempted to look up the H-index of the author if they don’t know the area very well. “I don’t really understand the paper by Professor Poindexter but he has an H-index of 95 so is obviously a good chap and his work is probably therefore world-leading”. That sort of thing.
I think this approach would be very wrong indeed. For a start, it seriously disadvantages early career researchers who haven’t had time to build up a back catalogue of high-impact papers. Secondly, and more fundamentally still, it is contrary to the stated aim of the REF, which is to assess only the research carried out in the assessment period, i.e. 2008 to 2013. The H-index would include papers going back far further than 2008.
But as I pointed out in my previous post, it’s going to be impossible for the panel to perform accurate assessments of all the papers they are given: there will just be far too many and too diverse in content. They will obviously therefore have to do something other than what the rest of the community has been told they will do. It’s a sorry state of affairs that dishonesty is built into the system, but there you go. Given that the panel will be forced to cheat, let me suggest that they at least do so fairly. Better than using the H-index of each individual, use the H-index calculated over the REF period only. That will at least ensure that only research done in the REF period will count towards the REF assessment.
Another bone of contention is the assessment of the level of contribution authors have made to each paper, in other words the question of attribution. In astronomy and particle physics, many important papers have very long author lists and may be submitted to the REF by many different authors in different institutions. We are told that what the panel will do is judge whether a given individual has made a “significant” contribution to the paper. If so, that author will be accredited with the score given to the paper. If not, the grade assigned will be the lowest and that author will get no credit at all. Under this scheme one could be an author on a 4* paper but be graded “U”.
This is fair enough, in that it will penalise the “lurkers” who have made a career by attaching their names to papers on which they have made negligible contributions. We know that such people exist. But how will the panel decide what contribution is significant and what isn’t? What is the criterion?
Take the following example. Suppose the Higgs Boson is discovered at the LHC duringthe REF period. Just about every particle physics group in the UK will have authors on the ensuing paper, but the list is likely to be immensely long and include people who performed many different roles. Who decides where to draw the line on “significance”. I really don’t know the answer to this one, but a possibility might be to found in the use of the textual commentary that accompanies the submission of a research output. At present we are told that this should be used to explain what the author’s contribution to the paper was, but as far as I’m aware there is no mechanism to stop individuals hyping up their involvement.What I mean is I don’t think the panel will check for consistency between commentaries submitted by different people for the same institution.
I’d suggest that consortia should be required to produce a standard form of words for the textual commentary, which will be used by every individual submitting the given paper and which lists all the other individuals in the UK submitting that paper as one of their four outputs. This will require co-authors to come to an agreement about their relative contributions in advance, which will no doubt lead to a lot of argument, but it seems to me the fairest way to do it. If the collaboration does not produce such an agreement then I suggest that paper be graded “U” throughout the exercise. This idea doesn’t answer the question “what does significant mean?”, but will at least put a stop to the worst of the game-playing that plagued the previous Research Assessment Exercise.
Another aspect of this relates to a question I asked several members of the Physics panel for the 2008 Research Assessment Exercise. Suppose Professor A at Oxbridge University and Dr B from The University of Neasden are co-authors on a paper and both choose to submit it as part of the REF return. Is there a mechanism to check that the grade given to the same piece of work is the same for both institutions? I never got a satisfactory answer in advance of the RAE but afterwards it became clear that the answer was “no”. I think that’s indefensible. I’d advise the panel to identify cases where the same paper is submitted by more than one institution and ensure that the grades they give are consistent.
Finally there’s the biggest problem. What on Earth does a grade like “4* (World Leading)” mean in the first place? This is clearly crucial because almost all the QR funding (in England at any rate) will be allocated to this grade. The percentage of outputs placed in this category varied enormously from field to field in the 2008 RAE and there is very strong evidence that the Physics panel judged much more harshly than the others. I don’t know what went on behind closed doors last time but whatever it was, it turned out to be very detrimental to the health of Physics as a discipline and the low fraction of 4* grades certainly did not present a fair reflection of the UK’s international standing in this area.
Ideally the REF panel could look at papers that were awarded 4* grades last time to see how the scoring went. Unfortunately, however, the previous panel shredded all this information, in order, one suspects, to avoid legal challenges. This more than any other individual act has led to deep suspicions amongs the Physics and Astronomy community about how the exercise was run. If I were in a position of influence I would urge the panel not to destroy the evidence. Most of us are mature enough to take disappointments in good grace as long as we trust the system. After all, we’re used to unsuccessful grant applications nowadays.
That’s about twice as much as I was planning to write so I’ll end on that, but if anyone else has concrete suggestions on how to repair the REF please file them through the comments box. They’ll probably be ignored, but you never know. Some members of the panel might take them on board.




 . We find that there is no compelling evidence that the QDOT dipole has converged within the limits of reliable determination and completeness. The value of
. We find that there is no compelling evidence that the QDOT dipole has converged within the limits of reliable determination and completeness. The value of  derived by
derived by 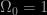 .
.
 . However, the Earth moves around the Sun. The Sun orbits the center of the
. However, the Earth moves around the Sun. The Sun orbits the center of the 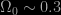 , with a large uncertainty. Now, 20 years later, we have a different standard cosmology which does indeed have
, with a large uncertainty. Now, 20 years later, we have a different standard cosmology which does indeed have  . We were right.
. We were right.




