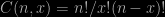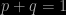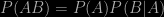After writing a post about spinning cricket balls a while ago I thought it might be fun to post something about the role of spin in quantum mechanics.
Spin is a concept of fundamental importance in quantum mechanics, not least because it underlies our most basic theoretical understanding of matter. The standard model of particle physics divides elementary particles into two types, fermions and bosons, according to their spin. One is tempted to think of these elementary particles as little cricket balls that can be rotating clockwise or anti-clockwise as they approach an elementary batsman. But, as I hope to explain, quantum spin is not really like classical spin: batting would be even more difficult if quantum bowlers were allowed!
Take the electron, for example. The amount of spin an electron carries is quantized, so that it always has a magnitude which is ±1/2 (in units of Planck’s constant; all fermions have half-integer spin). In addition, according to quantum mechanics, the orientation of the spin is indeterminate until it is measured. Any particular measurement can only determine the component of spin in one direction. Let’s take as an example the case where the measuring device is sensitive to the z-component, i.e. spin in the vertical direction. The outcome of an experiment on a single electron will lead a definite outcome which might either be “up” or “down” relative to this axis.
However, until one makes a measurement the state of the system is not specified and the outcome is consequently not predictable with certainty; there will be a probability of 50% probability for each possible outcome. We could write the state of the system (expressed by the spin part of its wavefunction ψ prior to measurement in the form
|ψ> = (|↑> + |↓>)/√2
This gives me an excuse to use the rather beautiful “bra-ket” notation for the state of a quantum system, originally due to Paul Dirac. The two possibilities are “up” (↑) and “down” (↓) and they are contained within a “ket” (written |>)which is really just a shorthand for a wavefunction describing that particular aspect of the system. A “bra” would be of the form <|; for the mathematicians this represents the Hermitian conjugate of a ket. The √2 is there to insure that the total probability of the spin being either up or down is 1, remembering that the probability is the square of the wavefunction. When we make a measurement we will get one of these two outcomes, with a 50% probability of each.
At the point of measurement the state changes: if we get “up” it becomes purely |↑> and if the result is “down” it becomes |↓>. Either way, the quantum state of the system has changed from a “superposition” state described by the equation above to an “eigenstate” which must be either up or down. This means that all subsequent measurements of the spin in this direction will give the same result: the wave-function has “collapsed” into one particular state. Incidentally, the general term for a two-state quantum system like this is a qubit, and it is the basis of the tentative steps that have been taken towards the construction of a quantum computer.
Notice that what is essential about this is the role of measurement. The collapse of ψ seems to be an irreversible process, but the wavefunction itself evolves according to the Schrödinger equation, which describes reversible, Hamiltonian changes. To understand what happens when the state of the wavefunction changes we need an extra level of interpretation beyond what the mathematics of quantum theory itself provides, because we are generally unable to write down a wave-function that sensibly describes the system plus the measuring apparatus in a single form.
So far this all seems rather similar to the state of a fair coin: it has a 50-50 chance of being heads or tails, but the doubt is resolved when its state is actually observed. Thereafter we know for sure what it is. But this resemblance is only superficial. A coin only has heads or tails, but the spin of an electron doesn’t have to be just up or down. We could rotate our measuring apparatus by 90° and measure the spin to the left (←) or the right (→). In this case we still have to get a result which is a half-integer times Planck’s constant. It will have a 50-50 chance of being left or right that “becomes” one or the other when a measurement is made.
Now comes the real fun. Suppose we do a series of measurements on the same electron. First we start with an electron whose spin we know nothing about. In other words it is in a superposition state like that shown above. We then make a measurement in the vertical direction. Suppose we get the answer “up”. The electron is now in the eigenstate with spin “up”.
We then pass it through another measurement, but this time it measures the spin to the left or the right. The process of selecting the electron to be one with spin in the “up” direction tells us nothing about whether the horizontal component of its spin is to the left or to the right. Theory thus predicts a 50-50 outcome of this measurement, as is observed experimentally.
Suppose we do such an experiment and establish that the electron’s spin vector is pointing to the left. Now our long-suffering electron passes into a third measurement which this time is again in the vertical direction. You might imagine that since we have already measured this component to be in the up direction, it would be in that direction again this time. In fact, this is not the case. The intervening measurement seems to “reset” the up-down component of the spin; the results of the third measurement are back at square one, with a 50-50 chance of getting up or down.
This is just one example of the kind of irreducible “randomness” that seems to be inherent in quantum theory. However, if you think this is what people mean when they say quantum mechanics is weird, you’re quite mistaken. It gets much weirder than this! So far I have focussed on what happens to the description of single particles when quantum measurements are made. Although there seem to be subtle things going on, it is not really obvious that anything happening is very different from systems in which we simply lack the microscopic information needed to make a prediction with absolute certainty.
At the simplest level, the difference is that quantum mechanics gives us a theory for the wave-function which somehow lies at a more fundamental level of description than the usual way we think of probabilities. Probabilities can be derived mathematically from the wave-function, but there is more information in ψ than there is in |ψ|2; the wave-function is a complex entity whereas the square of its amplitude is entirely real. If one can construct a system of two particles, for example, the resulting wave-function is obtained by superimposing the wave-functions of the individual particles, and probabilities are then obtained by squaring this joint wave-function. This will not, in general, give the same probability distribution as one would get by adding the one-particle probabilities because, for complex entities A and B,
A2+B2 ≠(A+B)2
in general. To put this another way, one can write any complex number in the form a+ib (real part plus imaginary part) or, generally more usefully in physics , as Reiθ, where R is the amplitude and θ is called the phase. The square of the amplitude gives the probability associated with the wavefunction of a single particle, but in this case the phase information disappears; the truly unique character of quantum physics and how it impacts on probabilies of measurements only reveals itself when the phase information is retained. This generally requires two or more particles to be involved, as the absolute phase of a single-particle state is essentially impossible to measure.
Finding situations where the quantum phase of a wave-function is important is not easy. It seems to be quite easy to disturb quantum systems in such a way that the phase information becomes scrambled, so testing the fundamental aspects of quantum theory requires considerable experimental ingenuity. But it has been done, and the results are astonishing.
Let us think about a very simple example of a two-component system: a pair of electrons. All we care about for the purpose of this experiment is the spin of the electrons so let us write the state of this system in terms of states such as which I take to mean that the first particle has spin up and the second one has spin down. Suppose we can create this pair of electrons in a state where we know the total spin is zero. The electrons are indistinguishable from each other so until we make a measurement we don’t know which one is spinning up and which one is spinning down. The state of the two-particle system might be this:
|ψ> = (|↑↓> – |↓↑>)/√2
squaring this up would give a 50% probability of “particle one” being up and “particle two” being down and 50% for the contrary arrangement. This doesn’t look too different from the example I discussed above, but this duplex state exhibits a bizarre phenomenon known as quantum entanglement.
Suppose we start the system out in this state and then separate the two electrons without disturbing their spin states. Before making a measurement we really can’t say what the spins of the individual particles are: they are in a mixed state that is neither up nor down but a combination of the two possibilities. When they’re up, they’re up. When they’re down, they’re down. But when they’re only half-way up they’re in an entangled state.
If one of them passes through a vertical spin-measuring device we will then know that particle is definitely spin-up or definitely spin-down. Since we know the total spin of the pair is zero, then we can immediately deduce that the other one must be spinning in the opposite direction because we’re not allowed to violate the law of conservation of angular momentum: if Particle 1 turns out to be spin-up, Particle 2 must be spin-down, and vice versa. It is known experimentally that passing two electrons through identical spin-measuring gadgets gives results consistent with this reasoning. So far there’s nothing so very strange in this.
The problem with entanglement lies in understanding what happens in reality when a measurement is done. Suppose we have two observers, Dick and Harry, each equipped with a device that can measure the spin of an electron in any direction they choose. Particle 1 emerges from the source and travels towards Dick whereas particle 2 travels in Harry’s direction. Before any measurement, the system is in an entangled superposition state. Suppose Dick decides to measure the spin of electron 1 in the z-direction and finds it spinning up. Immediately, the wave-function for electron 2 collapses into the down direction. If Dick had instead decided to measure spin in the left-right direction and found it “left” similar collapse would have occurred for particle 2, but this time putting it in the “right” direction.
Whatever Dick does, the result of any corresponding measurement made by Harry has a definite outcome – the opposite to Dick’s result. So Dick’s decision whether to make a measurement up-down or left-right instantaneously transmits itself to Harry who will find a consistent answer, if he makes the same measurement as Dick.
If, on the other hand, Dick makes an up-down measurement but Harry measures left-right then Dick’s answer has no effect on Harry, who has a 50% chance of getting “left” and 50% chance of getting right. The point is that whatever Dick decides to do, it has an immediate effect on the wave-function at Harry’s position; the collapse of the wave-function induced by Dick immediately collapses the state measured by Harry. How can particle 1 and particle 2 communicate in this way?
This riddle is the core of a thought experiment by Einstein, Podolsky and Rosen in 1935 which has deep implications for the nature of the information that is supplied by quantum mechanics. The essence of the EPR paradox is that each of the two particles – even if they are separated by huge distances – seems to know exactly what the other one is doing. Einstein called this “spooky action at a distance” and went on to point out that this type of thing simply could not happen in the usual calculus of random variables. His argument was later tightened considerably by John Bell in a form now known as Bell’s theorem.
To see how Bell’s theorem works, consider the following roughly analagous situation. Suppose we have two suspects in prison, say Dick and Harry (Tom grassed them up and has been granted immunity from prosecution). The two are taken apart to separate cells for individual questioning. We can allow them to use notes, electronic organizers, tablets of stone or anything to help them remember any agreed strategy they have concocted, but they are not allowed to communicate with each other once the interrogation has started. Each question they are asked has only two possible answers – “yes” or “no” – and there are only three possible questions. We can assume the questions are asked independently and in a random order to the two suspects.
When the questioning is over, the interrogators find that whenever they asked the same question, Dick and Harry always gave the same answer, but when the question was different they only gave the same answer 25% of the time. What can the interrogators conclude?
The answer is that Dick and Harry must be cheating. Either they have seen the question list ahead of time or are able to communicate with each other without the interrogator’s knowledge. If they always give the same answer when asked the same question, they must have agreed on answers to all three questions in advance. But when they are asked different questions then, because each question has only two possible responses, by following this strategy it must turn out that at least two of the three prepared answers – and possibly all of them – must be the same for both Dick and Harry. This puts a lower limit on the probability of them giving the same answer to different questions. I’ll leave it as an exercise to the reader to show that the probability of coincident answers to different questions in this case must be at least 1/3.
This a simple illustration of what in quantum mechanics is known as a Bell inequality. Dick and Harry can only keep the number of such false agreements down to the measured level of 25% by cheating.
This example is directly analogous to the behaviour of the entangled quantum state described above under repeated interrogations about its spin in three different directions. The result of each measurement can only be either “yes” or “no”. Each individual answer (for each particle) is equally probable in this case; the same question always produces the same answer for both particles, but the probability of agreement for two different questions is indeed ¼ and not larger as would be expected if the answers were random. For example one could ask particle 1 “are you spinning up” and particle 2 “are you spinning to the right”? The probability of both producing an answer “yes” is 25% according to quantum theory but would be higher if the particles weren’t cheating in some way.
Probably the most famous experiment of this type was done in the 1980s, by Alain Aspect and collaborators, involving entangled pairs of polarized photons (which are bosons), rather than electrons, primarily because these are easier to prepare.
The implications of quantum entanglement greatly troubled Einstein long before the EPR paradox. Indeed the interpretation of single-particle quantum measurement (which has no entanglement) was already troublesome. Just exactly how does the wave-function relate to the particle? What can one really say about the state of the particle before a measurement is made? What really happens when a wave-function collapses? These questions take us into philosophical territory that I have set foot in already; the difficult relationship between epistemological and ontological uses of probability theory.
Thanks largely to the influence of Niels Bohr, in the relatively early stages of quantum theory a standard approach to this question was adopted. In what became known as the Copenhagen interpretation of quantum mechanics, the collapse of the wave-function as a result of measurement represents a real change in the physical state of the system. Before the measurement, an electron really is neither spinning up nor spinning down but in a kind of quantum purgatory. After a measurement it is released from limbo and becomes definitely something. What collapses the wave-function is something unspecified to do with the interaction of the particle with the measuring apparatus or, in some extreme versions of this doctrine, the intervention of human consciousness.
I find it amazing that such a view could have been held so seriously by so many highly intelligent people. Schrödinger hated this concept so much that he invented a thought-experiment of his own to poke fun at it. This is the famous “Schrödinger’s cat” paradox. I’ve sent Columbo out of the room while I describe this.
In a closed box there is a cat. Attached to the box is a device which releases poison into the box when triggered by a quantum-mechanical event, such as radiation produced by the decay of a radioactive substance. One can’t tell from the outside whether the poison has been released or not, so one doesn’t know whether the cat is alive or dead. When one opens the box, one learns the truth. Whether the cat has collapsed or not, the wave-function certainly does. At this point one is effectively making a quantum measurement so the wave-function of the cat is either “dead” or “alive” but before opening the box it must be in a superposition state. But do we really think the cat is neither dead nor alive? Isn’t it certainly one or the other, but that our lack of information prevents us from knowing which? And if this is true for a macroscopic object such as a cat, why can’t it be true for a microscopic system, such as that involving just a pair of electrons?
As I learned at a talk by the Nobel prize-winning physicist Tony Leggett – who has been collecting data on this recently – most physicists think Schrödinger’s cat is definitely alive or dead before the box is opened. However, most physicists don’t believe that an electron definitely spins either up or down before a measurement is made. But where does one draw the line between the microscopic and macroscopic descriptions of reality? If quantum mechanics works for 1 particle, does it work also for 10, 1000? Or, for that matter, 1023?
Most modern physicists eschew the Copenhagen interpretation in favour of one or other of two modern interpretations. One involves the concept of quantum decoherence, which is basically the idea that the phase information that is crucial to the underlying logic of quantum theory can be destroyed by the interaction of a microscopic system with one of larger size. In effect, this hides the quantum nature of macroscopic systems and allows us to use a more classical description for complicated objects. This certainly happens in practice, but this idea seems to me merely to defer the problem of interpretation rather than solve it. The fact that a large and complex system makes tends to hide its quantum nature from us does not in itself give us the right to have a different interpretations of the wave-function for big things and for small things.
Another trendy way to think about quantum theory is the so-called Many-Worlds interpretation. This asserts that our Universe comprises an ensemble – sometimes called a multiverse – and probabilities are defined over this ensemble. In effect when an electron leaves its source it travels through infinitely many paths in this ensemble of possible worlds, interfering with itself on the way. We live in just one slice of the multiverse so at the end we perceive the electron winding up at just one point on our screen. Part of this is to some extent excusable, because many scientists still believe that one has to have an ensemble in order to have a well-defined probability theory. If one adopts a more sensible interpretation of probability then this is not actually necessary; probability does not have to be interpreted in terms of frequencies. But the many-worlds brigade goes even further than this. They assert that these parallel universes are real. What this means is not completely clear, as one can never visit parallel universes other than our own …
It seems to me that none of these interpretations is at all satisfactory and, in the gap left by the failure to find a sensible way to understand “quantum reality”, there has grown a pathological industry of pseudo-scientific gobbledegook. Claims that entanglement is consistent with telepathy, that parallel universes are scientific truths, that consciousness is a quantum phenomena abound in the New Age sections of bookshops but have no rational foundation. Physicists may complain about this, but they have only themselves to blame.
But there is one remaining possibility for an interpretation of that has been unfairly neglected by quantum theorists despite – or perhaps because of – the fact that is the closest of all to commonsense. This view that quantum mechanics is just an incomplete theory, and the reason it produces only a probabilistic description is that does not provide sufficient information to make definite predictions. This line of reasoning has a distinguished pedigree, but fell out of favour after the arrival of Bell’s theorem and related issues. Early ideas on this theme revolved around the idea that particles could carry “hidden variables” whose behaviour we could not predict because our fundamental description is inadequate. In other words two apparently identical electrons are not really identical; something we cannot directly measure marks them apart. If this works then we can simply use only probability theory to deal with inferences made on the basis of information that’s not sufficient for absolute certainty.
After Bell’s work, however, it became clear that these hidden variables must possess a very peculiar property if they are to describe out quantum world. The property of entanglement requires the hidden variables to be non-local. In other words, two electrons must be able to communicate their values faster than the speed of light. Putting this conclusion together with relativity leads one to deduce that the chain of cause and effect must break down: hidden variables are therefore acausal. This is such an unpalatable idea that it seems to many physicists to be even worse than the alternatives, but to me it seems entirely plausible that the causal structure of space-time must break down at some level. On the other hand, not all “incomplete” interpretations of quantum theory involve hidden variables.
One can think of this category of interpretation as involving an epistemological view of quantum mechanics. The probabilistic nature of the theory has, in some sense, a subjective origin. It represents deficiencies in our state of knowledge. The alternative Copenhagen and Many-Worlds views I discussed above differ greatly from each other, but each is characterized by the mistaken desire to put quantum mechanics – and, therefore, probability – in the realm of ontology.
The idea that quantum mechanics might be incomplete (or even just fundamentally “wrong”) does not seem to me to be all that radical. Although it has been very successful, there are sufficiently many problems of interpretation associated with it that perhaps it will eventually be replaced by something more fundamental, or at least different. Surprisingly, this is a somewhat heretical view among physicists: most, including several Nobel laureates, seem to think that quantum theory is unquestionably the most complete description of nature we will ever obtain. That may be true, of course. But if we never look any deeper we will certainly never know…
With the gradual re-emergence of Bayesian approaches in other branches of physics a number of important steps have been taken towards the construction of a truly inductive interpretation of quantum mechanics. This programme sets out to understand probability in terms of the “degree of belief” that characterizes Bayesian probabilities. Recently, Christopher Fuchs, amongst others, has shown that, contrary to popular myth, the role of probability in quantum mechanics can indeed be understood in this way and, moreover, that a theory in which quantum states are states of knowledge rather than states of reality is complete and well-defined. I am not claiming that this argument is settled, but this approach seems to me by far the most compelling and it is a pity more people aren’t following it up…