This morning I came across the following quotation, which is translated from the book Le Pesanteur et la Grace (i.e. “Gravity and Grace“), written in 1947 by French philosopher Simone Weil:
Science today must search for a source of inspiration higher than itself or it must perish.
Science offers only three points of interest: 1. technical applications; 2. as a game of chess; 3. as a way to God.
I’m not sure I agree with what is written, and in any case the options don’t seem to me to be mutually exclusive, but a number of things did strike me reading it.
For a start, and for what it’s worth, I do think science has value within itself, so I’m at odds a bit with the initial premise. On the other hand, science is a human activity and it therefore doesn’t stand apart from other thing humans are interested in.
Then there is the extent to which we now all have to pretend that pretty much the only point of interest in science is “1. technical applications”. I don’t believe that’s true, actually, and I’m worried that by continually saying that it is, scientists might be sowing the seeds of their own destruction.
And then there’s “the game of chess”. I’m actually hopeless at chess, but I understand this as representing some form of abstract mental challenge. If that’s what it does mean, then I’d agree that’s probably what got me interested in science. I’ve always been pathologically interested in puzzles. When I look at galaxies and stars, I don’t tend to gaze at them in awe at their enormity or beauty, I just tend to wonder how they work and what they’re made of. I don’t really mind people having a sense of awe, of course, but there’s a danger that if we take that too far we end up being over-awed which might make us shy away from the biggest questions. To me the Universe is just a great big puzzle, though it’s actually rather a tough one. I’m still stuck on 1 across, in fact…
Finally, we have science as “a way to God”. I find it quite interesting that a Christian philosopher could present science as that, especially when so many of my atheistic colleagues regard science and religion as polar opposites. It seems likely to me that anyone who studies science primarily as a means of finding God is probably in for a disappointment. I’m reminded of a quote from Thomas à Kempis I learned at school:
The humble knowledge of thyself is a surer way to God than the deepest search after science.
But that’s not to say that science and religion are incompatible with each other. I think they’re basically orthogonal, although in an abstract space with an extremely complicated geometry…
One of the interesting things about working in cosmology is that the big questions are very big indeed, which may be the reason why cosmologists tend to have strong views on matters of religion (and metaphysics in a general sense). Just take the Templeton Prize, for example. The arguments about this year’s award to Lord (Martin) Rees are still simmering on, but it’s worth remembering that many recent winners of this prize, including John Barrow (my PhD supervisor, in fact) and George Ellis (former collaborator of mine), are most noted for their work in cosmology. Both are religious: John Barrow is a member of the United Reformed Church, and George Ellis is a Quaker. Martin Rees is an atheist. But their religious views are not in conflict with their research. All are outstanding scientists.
I’ve been thinking a lot over the Easter holiday about religion and science. It’s partly the Templeton prize saga, partly the occasion of Easter itself, and partly the fact that I’ve been reading even more of the poems of R.S. Thomas. In case you didn’t know I was brought up in the (Anglican) Christian tradition, attended Sunday School, sang in the local Church Choir, and was confirmed in the Church of England. When I went to seconday school – the Royal Grammar School, Newcastle – I joined the Christian Union and remained in it for 3-4 years.
Although I was immersed in Christianity – the Christian Union was vigorously Evangelical – it didn’t really stick and eventually all melted away. I don’t really remember precisely what it was then that made me turn away from religion, although the sins of the flesh might have had something to do with it…
However, although I became an atheist I’ve never been a particularly devout one. The only thing that I’m really sure about is that I don’t know the answers. Does that make me an agnostic rather than an atheist? I don’t know. Perhaps I could just describe myself as a non-believer? That wouldn’t do either, because we all have to believe in some things in order to function at all. Even science starts with unprovable axioms.
A career in cosmology has given me the opportunity to think about many Big Questions. Why does the Universe have laws? Why is there something rather than nothing? And so on. I’m not much of a philosopher, though, and I don’t have the answers. I do, however, refuse to take the easy way out by denying that the questions have meaning. Of course it’s not entirely satisfactory having to answer “I don’t know”, but I don’t agree with those of my atheist colleagues who think religion is an easy way out. I’m sure that a thinking Christian has just as many difficult issues to grapple with as a thinking atheist. Not thinking at all is the only really easy way out.
A few years ago I spoke at an interesting meeting in Cambridge entitled God or Multiverse? In fact there’s a picture below of the panel discussion at the end -I’m second from the right:

I thought it was an interesting dialogue, but I have to say that, if anything, it strengthened my non-belief. Prof. Keith Ward argued that the primary motivation for belief in God was the existence of “Good”. I have to admit that I find the Universe as a whole amoral and although humans have done good from time to time they have done evil in at least equal measure. The vast majority of people on this Earth live in poverty, many of them in abject misery. Good is a bad word to describe this state of affairs.
I just can’t accept the idea of a God that is interested in the Universe at the level of human beings. We’re so insignificant on the scale of the cosmos, that it seems very arrogant to me to suppose that it’s really got much to do with us. We appeared somehow, miraculously perhaps, but could disappear just as easily. I doubt the Universe would miss us much.
But I might be wrong.
![]()
 , but we fear it may not fit the data. We therefore add a couple more parameters, say
, but we fear it may not fit the data. We therefore add a couple more parameters, say 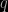 and
and  . These might be the coefficients of a polynomial fit, for example: the first model might be straight line (with fixed intercept), the second a cubic. We don’t know the appropriate numerical values for the parameters at the outset, so we must infer them by comparison with the available data.
. These might be the coefficients of a polynomial fit, for example: the first model might be straight line (with fixed intercept), the second a cubic. We don’t know the appropriate numerical values for the parameters at the outset, so we must infer them by comparison with the available data. which has a set of
which has a set of 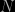 floating parameters represented as a vector
floating parameters represented as a vector  ; in a sense each choice of parameters represents a different model or, more precisely, a member of the family of models labelled
; in a sense each choice of parameters represents a different model or, more precisely, a member of the family of models labelled 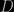 and can consequently form a likelihood function
and can consequently form a likelihood function 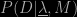 . In Bayesian reasoning we have to assign a prior probability
. In Bayesian reasoning we have to assign a prior probability 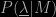 to the parameters of the model which, if we’re being honest, we should do in advance of making any measurements!
to the parameters of the model which, if we’re being honest, we should do in advance of making any measurements! but the extent to which the data support the model in general. This is encoded in a sort of average of likelihood over the prior probability space:
but the extent to which the data support the model in general. This is encoded in a sort of average of likelihood over the prior probability space:
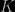 usually found in statements of Bayes’ theorem which, in this context, takes the form
usually found in statements of Bayes’ theorem which, in this context, takes the form
 parameters lower than that for the
parameters lower than that for the 
