I don’t know how many followers of this blog are interested in Chemistry, but I thought I’d continue my irregular series of postings of old examination papers with my Chemistry A-level. This particular Paper was Paper 1 of 2 (although I did also take the “special” Paper 3). As you can see Paper 1 was of multiple-choice format, with 40 questions to answer in 75 minutes, which seems a bit stiff! Looking over the exam just now I can’t believe that there was a time when I actually knew this stuff. Nowadays I can only really do the first few questions – because they’re really physics – and I don’t even remember what most of the words mean in the other questions!
Anyway, as usual, any comments from people who’ve done A-level Chemistry more recently would be very welcome through the Comments Box, e.g. is there anything in this paper that you wouldn’t expect to see nowadays? Is it easier, harder, or about the same as current A-level Chemistry papers?
A recent article in New Scientistreminded me that I never completed the story I started with a couple of earlier posts (here and there), so while I wait for the rain to stop I thought I’d make myself useful by posting something now. It’s all about a paper available on the arXiv by Scrimgeour et al. concerning the transition to homogeneity of galaxy clustering in the WiggleZ galaxy survey, the abstract of which reads:
We have made the largest-volume measurement to date of the transition to large-scale homogeneity in the distribution of galaxies. We use the WiggleZ survey, a spectroscopic survey of over 200,000 blue galaxies in a cosmic volume of ~1 (Gpc/h)^3. A new method of defining the ‘homogeneity scale’ is presented, which is more robust than methods previously used in the literature, and which can be easily compared between different surveys. Due to the large cosmic depth of WiggleZ (up to z=1) we are able to make the first measurement of the transition to homogeneity over a range of cosmic epochs. The mean number of galaxies N(<r) in spheres of comoving radius r is proportional to r^3 within 1%, or equivalently the fractal dimension of the sample is within 1% of D_2=3, at radii larger than 71 \pm 8 Mpc/h at z~0.2, 70 \pm 5 Mpc/h at z~0.4, 81 \pm 5 Mpc/h at z~0.6, and 75 \pm 4 Mpc/h at z~0.8. We demonstrate the robustness of our results against selection function effects, using a LCDM N-body simulation and a suite of inhomogeneous fractal distributions. The results are in excellent agreement with both the LCDM N-body simulation and an analytical LCDM prediction. We can exclude a fractal distribution with fractal dimension below D_2=2.97 on scales from ~80 Mpc/h up to the largest scales probed by our measurement, ~300 Mpc/h, at 99.99% confidence.
To paraphrase, the conclusion of this study is that while galaxies are strongly clustered on small scales – in a complex `cosmic web’ of clumps, knots, sheets and filaments – on sufficiently large scales, the Universe appears to be smooth. This is much like a bowl of porridge which contains many lumps, but (usually) none as large as the bowl it’s put in.
Our standard cosmological model is based on the Cosmological Principle, which asserts that the Universe is, in a broad-brush sense, homogeneous (is the same in every place) and isotropic (looks the same in all directions). But the question that has troubled cosmologists for many years is what is meant by large scales? How broad does the broad brush have to be?
I blogged some time ago about that the idea that the Universe might have structure on all scales, as would be the case if it were described in terms of a fractal set characterized by a fractal dimension . In a fractal set, the mean number of neighbours of a given galaxy within a spherical volume of radius is proportional to . If galaxies are distributed uniformly (homogeneously) then , as the number of neighbours simply depends on the volume of the sphere, i.e. as , and the average number-density of galaxies. A value of indicates that the galaxies do not fill space in a homogeneous fashion: , for example, would indicate that galaxies were distributed in roughly linear structures (filaments); the mass of material distributed along a filament enclosed within a sphere grows linear with the radius of the sphere, i.e. as , not as its volume; galaxies distributed in sheets would have , and so on.
We know that on small scales (in cosmological terms, still several Megaparsecs), but the evidence for a turnover to has not been so strong, at least not until recently. It’s just just that measuring from a survey is actually rather tricky, but also that when we cosmologists adopt the Cosmological Principle we apply it not to the distribution of galaxies in space, but to space itself. We assume that space is homogeneous so that its geometry can be described by the Friedmann-Lemaitre-Robertson-Walker metric.
According to Einstein’s theory of general relativity, clumps in the matter distribution would cause distortions in the metric which are roughly related to fluctuations in the Newtonian gravitational potential by , give or take a factor of a few, so that a large fluctuation in the density of matter wouldn’t necessarily cause a large fluctuation of the metric unless it were on a scale reasonably large relative to the cosmological horizon . Galaxies correspond to a large but don’t violate the Cosmological Principle because they are too small in scale to perturb the background metric significantly.
The discussion of a fractal universe is one I’m overdue to return to. In my previous post I left the story as it stood about 15 years ago, and there have been numerous developments since then, not all of them consistent with each other. I will do a full “Part 2” to that post eventually, but in the mean time I’ll just comment that this particularly one does seem to be consistent with a Universe that possesses the property of large-scale homogeneity. If that conclusion survives the next generation of even larger galaxy redshift surveys then it will come as an immense relief to cosmologists.
The reason for that is that the equations of general relativity are very hard to solve in cases where there isn’t a lot of symmetry; there are just too many equations to solve for a general solution to be obtained. If the cosmological principle applies, however, the equations simplify enormously (both in number and form) and we can get results we can work with on the back of an envelope. Small fluctuations about the smooth background solution can be handled (approximately but robustly) using a technique called perturbation theory. If the fluctuations are large, however, these methods don’t work. What we need to do instead is construct exact inhomogeneous model, and that is very very hard. It’s of course a different question as to why the Universe is so smooth on large scales, but as a working cosmologist the real importance of it being that way is that it makes our job so much easier than it would otherwise be.
P.S. And I might add that the importance of the Scrimgeour et al paper to me personally is greatly amplified by the fact that it cites a number of my own articles on this theme!
Never let me lose the marvel of your statue-like eyes, or the accent the solitary rose of your breath places on my cheek at night. I am afraid of being, on this shore, a branchless trunk, and what I most regret is having no flower, pulp, or clay for the worm of my despair. If you are my hidden treasure, if you are my cross, my dampened pain, if I am a dog, and you alone my master, never let me lose what I have gained, and adorn the branches of your river with leaves of my estranged Autumn.
This poem is from a collection called Sonetos del amor oscuro (“Sonnets of Dark Love”), which contains the last verses ever written by Lorca. They were written to a young man, with whom the poet had a secret love affair, whose identity remained unknown until earlier this year (2012) when letters and other documents were found which revealed him to be the (then) 19-year old Juan Ramírez de Lucas.
Regular readers of this blog (Sid and Doris Bonkers) may recall that a few weeks ago I posted an item in which I suggested setting up The Open Journal of Astrophysics. The motivation behind this was to demonstrate that it is possible to run an academic journal which is freely available to anyone who wants to read it, as well as at minimal cost to authors. Basically, I want to show that it is possible to “cut out the middle man” in the process of publishing scientific research and that by doing it ourselves we can actually do it better.
I have been unwell for much of the summer, so haven’t been able to carry this project on as much as I would have liked, and I also received many messages offering help and advice that I have been unable to reply to individually. But I can assure you that I haven’t forgotten about the idea, nor have I quietly withdrawn the financial backing I suggested in my earlier post. Indeed, my interest in, and excitement, about this project has grown significantly over the summer as new possibilities have been suggested and my resentment about how the academic publishing industry hijacked the Finch Report has deepened.
In fact, quite a lot of effort has already been put in by people elsewhere thinking about how to set this journal up in the best way to make maximal use of digital technology to produce something radically different from the stale formats offered by existing journals. I hope to be able to report back soon with more details of how it will work, when we propose to launch the site, and even what its name will be, Open Journal of Astrophysics being just a working title. I think it’s far better to wait until we have a full prototype going before going further.
In the meantime, however, I have a request to make. The Open Journal of Astrophysics will need an Editorial Board with expertise across all astrophysics, so they can select referees and deal with the associated correspondence. The success of this venture will largely depend on establishing trust with the research community and one way of doing that will be by having eminent individuals on the Editorial Board. I will be contacting privately various scientists who have already offered their assistance in this, but if any senior astronomers and/or astrophysicists out there are interested in playing a part please contact me. I can’t offer much in the way of remuneration, but I think this is an opportunity to get involved in a venture that in the long run will benefit the astronomical community immensely.
Oh, and please feel free pass this on to folks you think might be interested even if you yourself are not!
I haven’t posted any jazzy bits for a while. I don’t know why. Anyway, I just found this track, called Ablution, by alto saxophonist Lee Konitz. Unless my ears deceive me the pianist on this track is Ronnie Ball (British, by the way) whose comping makes no attempt to disguise the fact that it is a variation on the famous Jerome Kern tune All The Things You Are, the unusual chords of which have made it a popular vehicle for jazz musicians to improvise on ever since it was written back in 1939. In the bebop era it was typical practice to base original compositions on top of the chord sequences of standard tunes, and this is a prime example although I don’t know in this case whether Lee Konitz managed to get away without paying composer’s royalties!
Judging by the furore surrounding the last-minute marking down of GCSE English Language examinations this year, I thought it might be interesting to put the old scanner to work and show you the English Language examinations I took at age 16, way back in 1979. In those days the GCSE hadn’t been invented yet, and instead we had two different systems GCE O Level (which I took) and CSE. Anyway, these be the papers what I sat.
The one thing that surprises me a little in retrospect is the considerable emphasis on poetry in the second paper, which I now think would belong more in an English Literature paper. However, there’s no doubt that my schooldays instilled in me a lifelong love of poetry and for that I won’t complain at all…
I’d be very interested in any comments about the difference in style and content between these and modern-day GCSE English Language.
P.S. If you’re wondering what happened to Page 2 of Paper 1, it’s completely blank so I didn’t scan it.
I’ve been meaning for a while to post a little tribute to British composer James Bernard, and this Bank Holiday Weekend has left me with a bit of time to do so now. Most of you are probably wondering who James Bernard is (or was; he died in 2001), but many of you will have heard his music many times without realising it, for he was the composer who wrote most of the music for the classic British horror movies made by Hammer Film Productions from the late 1950s through to the 1970s.
I’m by no means an aficionado of horror films – or films of any sort for that matter, as I rarely go to the cinema these days – but I do enjoy the opera, which is probably why I find these films so interesting. I don’t think they would have established themselves as the classics there without the unique atmosphere conjured up by James Bernard’s scores. Nor without such fine actors as Christopher Lee and Peter Cushing, of course. The reason for this is that’s not much in these films in terms of purely visual horror – they work so well by creating an undertone of dread and impending terror so that the viewers’ own imaginations frighten them more than what’s shown on the screen. Viewed without the music, most of these films look pretty tame although I have to say I think The Devil Rides Out would have had me hiding behind the sofa even without the music!
Here is a little taste of what is probably his most famous score, for The Horror of Dracula (1958) which starred the inimitable Christopher Lee in the title role.
I think there are two things worth mentioning about this particular piece. The first is that the main theme is built around a three-note motif inspired by the three syllables of the name “Dra-cu-la”. Even more interestingly, Bernard doubles that line in the orchestra a whole tone higher, the resulting clash of harmonies producing that jarring sound that ratchets up the psychological tension. It’s a simple device, but remarkably effective, especially when combined with the unusual percussion.
The second thing that struck me listening to this just now is how reminiscent the entry of the high strings (about 0:49) is of the orchestration of the sea interludes from Benjamin Britten’s opera Peter Grimes. That’s not a surprise at all, because James Bernard was a childhood friend of Britten, and they worked together at various times in later life. Bernard’s music is often atonal and sometimes puts me in mind of Britten’s gripping opera A Turn of the Screw, based on the famous ghost story by Henry James, which also uses atonal techniques to produce an unsettling musical undercurrent. Alban Berg’s opera Lulu (a performance of which I reviewed here) also springs to mind as one in which the lack of a tonal centre in the music produces an atmosphere of disorientation and inner dread.
The other day I had a slight disagreement with a colleague of mine about the best advice to give to new PhD students about how to tackle their research. Talking to a few other members of staff about it subsequently has convinced me that there isn’t really a consensus about it and it might therefore be worth a quick post to see what others think.
Basically the issue is whether a new research student should try to get into “hands-on” research as soon as he or she starts, or whether it’s better to spend most of the initial phase in preparation: reading all the literature, learning the techniques required, taking advanced theory courses, and so on. I know that there’s usually a mixture of these two approaches, and it will vary hugely from one discipline to another, and especially between theory and experiment, but the question is which one do you think should dominate early on?
My view of this is coloured by my own experience as a PhD (or rather DPhil student) twenty-five years ago. I went directly from a three-year undergraduate degree to a three-year postgraduate degree. I did a little bit of background reading over the summer before I started graduate studies, but basically went straight into trying to solve a problem my supervisor gave me when I arrived at Sussex to start my DPhil. I had to learn quite a lot of stuff as I went along in order to get on, which I did in a way that wasn’t at all systematic.
Fortunately I did manage to crack the problem I was given, with the consequence that got a publication out quite early during my thesis period. Looking back on it I even think that I was helped by the fact that I was too ignorant to realise how difficult more expert people thought the problem was. I didn’t know enough to be frightened. That’s the drawback with the approach of reading everything about a field before you have a go yourself…
In the case of the problem I had to solve, which was actually more to do with applied probability theory than physics, I managed to find (pretty much by guesswork) a cute mathematical trick that turned out to finesse the difficult parts of the calculation I had to do. I really don’t think I would have had the nerve to try such a trick if I had read all the difficult technical literature on the subject.
So I definitely benefited from the approach of diving headlong straight into the detail, but I’m very aware that it’s difficult to argue from the particular to the general. Clearly research students need to do some groundwork; they have to acquire a toolbox of some sort and know enough about the field to understand what’s worth doing. But what I’m saying is that sometimes you can know too much. All that literature can weigh you down so much that it actually stifles rather than nurtures your ability to do research. But then complete ignorance is no good either. How do you judge the right balance?
I’d be interested in comments on this, especially to what extent it is an issue in fields other than astrophysics.
A few days ago an article appeared on the BBC website that discussed the enduring appeal of Sherlock Holmes and related this to the processes involved in solving puzzles. That piece makes a number of points I’ve made before, so I thought I’d update and recycle my previous post on that theme. The main reason for doing so is that it gives me yet another chance to pay homage to the brilliant Jeremy Brett who, in my opinion, is unsurpassed in the role of Sherlock Holmes. It also allows me to return to a philosophical theme I visited earlier this week.
One of the things that fascinates me about detective stories (of which I am an avid reader) is how often they use the word “deduction” to describe the logical methods involved in solving a crime. As a matter of fact, what Holmes generally uses is not really deduction at all, but inference (a process which is predominantly inductive).
In deductive reasoning, one tries to tease out the logical consequences of a premise; the resulting conclusions are, generally speaking, more specific than the premise. “If these are the general rules, what are the consequences for this particular situation?” is the kind of question one can answer using deduction.
The kind of reasoning of reasoning Holmes employs, however, is essentially opposite to this. The question being answered is of the form: “From a particular set of observations, what can we infer about the more general circumstances that relating to them?”.
And for a dramatic illustration of the process of inference, you can see it acted out by the great Jeremy Brett in the first four minutes or so of this clip from the classic Granada TV adaptation of The Hound of the Baskervilles:
I think it’s pretty clear in this case that what’s going on here is a process of inference (i.e. inductive rather than deductive reasoning). It’s also pretty clear, at least to me, that Jeremy Brett’s acting in that scene is utterly superb.
I’m probably labouring the distinction between induction and deduction, but the main purpose doing so is that a great deal of science is fundamentally inferential and, as a consequence, it entails dealing with inferences (or guesses or conjectures) that are inherently uncertain as to their application to real facts. Dealing with these uncertain aspects requires a more general kind of logic than the simple Boolean form employed in deductive reasoning. This side of the scientific method is sadly neglected in most approaches to science education.
In physics, the attitude is usually to establish the rules (“the laws of physics”) as axioms (though perhaps giving some experimental justification). Students are then taught to solve problems which generally involve working out particular consequences of these laws. This is all deductive. I’ve got nothing against this as it is what a great deal of theoretical research in physics is actually like, it forms an essential part of the training of an physicist.
However, one of the aims of physics – especially fundamental physics – is to try to establish what the laws of nature actually are from observations of particular outcomes. It would be simplistic to say that this was entirely inductive in character. Sometimes deduction plays an important role in scientific discoveries. For example, Albert Einstein deduced his Special Theory of Relativity from a postulate that the speed of light was constant for all observers in uniform relative motion. However, the motivation for this entire chain of reasoning arose from previous studies of eletromagnetism which involved a complicated interplay between experiment and theory that eventually led to Maxwell’s equations. Deduction and induction are both involved at some level in a kind of dialectical relationship.
The synthesis of the two approaches requires an evaluation of the evidence the data provides concerning the different theories. This evidence is rarely conclusive, so a wider range of logical possibilities than “true” or “false” needs to be accommodated. Fortunately, there is a quantitative and logically rigorous way of doing this. It is called Bayesian probability. In this way of reasoning, the probability (a number between 0 and 1 attached to a hypothesis, model, or anything that can be described as a logical proposition of some sort) represents the extent to which a given set of data supports the given hypothesis. The calculus of probabilities only reduces to Boolean algebra when the probabilities of all hypothesese involved are either unity (certainly true) or zero (certainly false). In between “true” and “false” there are varying degrees of “uncertain” represented by a number between 0 and 1, i.e. the probability.
Overlooking the importance of inductive reasoning has led to numerous pathological developments that have hindered the growth of science. One example is the widespread and remarkably naive devotion that many scientists have towards the philosophy of the anti-inductivist Karl Popper; his doctrine of falsifiability has led to an unhealthy neglect of an essential fact of probabilistic reasoning, namely that data can make theories more probable. More generally, the rise of the empiricist philosophical tradition that stems from David Hume (another anti-inductivist) spawned the frequentist conception of probability, with its regrettable legacy of confusion and irrationality.
In fact Sherlock Holmes himself explicitly recognizes the importance of inference and rejects the one-sided doctrine of falsification. Here he is in The Adventure of the Cardboard Box (the emphasis is mine):
Let me run over the principal steps. We approached the case, you remember, with an absolutely blank mind, which is always an advantage. We had formed no theories. We were simply there to observe and to draw inferences from our observations. What did we see first? A very placid and respectable lady, who seemed quite innocent of any secret, and a portrait which showed me that she had two younger sisters. It instantly flashed across my mind that the box might have been meant for one of these. I set the idea aside as one which could be disproved or confirmed at our leisure.
My own field of cosmology provides the largest-scale illustration of this process in action. Theorists make postulates about the contents of the Universe and the laws that describe it and try to calculate what measurable consequences their ideas might have. Observers make measurements as best they can, but these are inevitably restricted in number and accuracy by technical considerations. Over the years, theoretical cosmologists deductively explored the possible ways Einstein’s General Theory of Relativity could be applied to the cosmos at large. Eventually a family of theoretical models was constructed, each of which could, in principle, describe a universe with the same basic properties as ours. But determining which, if any, of these models applied to the real thing required more detailed data. For example, observations of the properties of individual galaxies led to the inferred presence of cosmologically important quantities of dark matter. Inference also played a key role in establishing the existence of dark energy as a major part of the overall energy budget of the Universe. The result is now that we have now arrived at a standard model of cosmology which accounts pretty well for most relevant data.
Nothing is certain, of course, and this model may well turn out to be flawed in important ways. All the best detective stories have twists in which the favoured theory turns out to be wrong. But although the puzzle isn’t exactly solved, we’ve got good reasons for thinking we’re nearer to at least some of the answers than we were 20 years ago.
The views presented here are personal and not necessarily those of my employer (or anyone else for that matter).
Feel free to comment on any of the posts on this blog but comments may be moderated; anonymous comments and any considered by me to be vexatious and/or abusive and/or defamatory will not be accepted. I do not necessarily endorse, support, sanction, encourage, verify or agree with the opinions or statements of any information or other content in the comments on this site and do not in any way guarantee their accuracy or reliability.
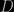 . In a fractal set, the mean number of neighbours of a given galaxy within a spherical volume of radius
. In a fractal set, the mean number of neighbours of a given galaxy within a spherical volume of radius  is proportional to
is proportional to 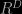 . If galaxies are distributed uniformly (homogeneously) then
. If galaxies are distributed uniformly (homogeneously) then  , as the number of neighbours simply depends on the volume of the sphere, i.e. as
, as the number of neighbours simply depends on the volume of the sphere, i.e. as 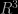 , and the average number-density of galaxies. A value of
, and the average number-density of galaxies. A value of 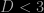 indicates that the galaxies do not fill space in a homogeneous fashion:
indicates that the galaxies do not fill space in a homogeneous fashion:  , for example, would indicate that galaxies were distributed in roughly linear structures (filaments); the mass of material distributed along a filament enclosed within a sphere grows linear with the radius of the sphere, i.e. as
, for example, would indicate that galaxies were distributed in roughly linear structures (filaments); the mass of material distributed along a filament enclosed within a sphere grows linear with the radius of the sphere, i.e. as  , not as its volume; galaxies distributed in sheets would have
, not as its volume; galaxies distributed in sheets would have 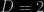 , and so on.
, and so on.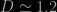 on small scales (in cosmological terms, still several Megaparsecs), but the evidence for a turnover to
on small scales (in cosmological terms, still several Megaparsecs), but the evidence for a turnover to  has not been so strong, at least not until recently. It’s just just that measuring
has not been so strong, at least not until recently. It’s just just that measuring 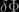 by
by 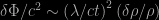 , give or take a factor of a few, so that a large fluctuation in the density of matter wouldn’t necessarily cause a large fluctuation of the metric unless it were on a scale
, give or take a factor of a few, so that a large fluctuation in the density of matter wouldn’t necessarily cause a large fluctuation of the metric unless it were on a scale 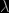 reasonably large relative to the cosmological horizon
reasonably large relative to the cosmological horizon  . Galaxies correspond to a large
. Galaxies correspond to a large  but don’t violate the Cosmological Principle because they are too small in scale
but don’t violate the Cosmological Principle because they are too small in scale 


