I was just thinking that it’s been a while since I posted anything in my bad statistics category when a particularly egregious example jumped up out of this week’s Times Higher and slapped me in the face. This one goes wrong before it even gets to the statistical analysis, so I’ll only give it short shrift here, but it serves to remind us all how feeble is many academic’s grasp of the scientific method, and particularly the role of statistics within it. The perpetrator in this case is Paul Whiteley, who is Professor of Politics at the University of Essex. I’m tempted to suggest he should go and stand in the corner wearing a dunce’s cap.
Professor Whiteley argues that he has found evidence that refutes the case that increased provision of science, technology, engineering and maths (STEM) graduates are -in the words of Lord Mandelson – “crucial to in securing future prosperity”. His evidence is based on data relating to 30 OECD countries: on the one hand, their average economic growth for the period 2000-8 and, on the other, the percentage of graduates in STEM subjects for each country over the same period. He finds no statistically significant correlation between these variates. The data are plotted here:

This lack of correlation is asserted to be evidence that STEM graduates are not necessary for economic growth, but in an additional comment (for which no supporting numbers are given), it is stated that growth correlates with the total number of graduates in all subjects in each country. Hence the conclusion that higher education is good, whether or not it’s in STEM areas.
So what’s wrong with this analysis? A number of things, in fact, but I’ll start with what seems to me the most important conceptual one. In order to test a hypothesis, you have to look for a measurable effect that would be expected if the hypothesis were true, measure the effect, and then decide whether the effect is there or not. If it isn’t, you have falsified the hypothesis.
Now, would anyone really expect the % of students graduating in STEM subjects to correlate with the growth rate in the economy over the same period? Does anyone really think that newly qualified STEM graduates have an immediate impact on economic growth? I’m sure even the most dedicated pro-science lobbyist would answer “no” to that question. Even the quote from Lord Mandelson included the crucial word “future”! Investment in these areas is expected to have a long-term benefit that would probably only show after many years. I would have been amazed had there been a correlation between measures relating to such a short period, so absence of one says nothing whatsoever about the economic benefits of education in STEM areas.
And another thing. Why is the “percentage of graduates” chosen as a variate for this study? Surely a large % of STEM graduates is irrelevant if the total number is very small? I would have thought the fraction of the population with a STEM degree might be a better choice. Better still, since it is claimed that the overall number of graduates correlates with economic growth, why not show how this correlation with the total number of graduates breaks down by subject area?
I’m a bit suspicious about the reliability of the data too. Which country is it that produces less than 3% of its graduates in science subjects (the point at the bottom left of the plot). Surely different countries also have different types of economy wherein the role of science and technology varies considerably. It’s tempting, in fact, to see two parallel lines in the above graph – I’m not the only one to have noticed this – which may either be an artefact of small numbers chosen or might indicate that some other parameter is playing a role.
This poorly framed hypothesis test, dubious choice of variables, and highly questionable conclusions strongly suggest that Professor Whiteley had made his mind up what result he wanted and simply dressed it up in a bit of flimsy statistics. Unfortunately, such pseudoscientific flummery is all that’s needed to convince a great many out there in the big wide world, especially journalists. It’s a pity that this shoddy piece of statistical gibberish was given such prominence in the Times Higher, supported by a predictably vacuous editorial, especially when the same issue features an article about the declining standards of science journalism. Perhaps we need more STEM graduates to teach the others how to do statistical tests properly.
However, before everyone accuses me of being blind to the benefits of anything other than STEM subjects, I’ll just make it clear that, while I do think that science is very important for a large number of reasons, I do accept that higher education generally is a good thing in itself , regardless of whether it’s in physics or mediaeval latin, though I’m not sure about certain other subjects. Universities should not be judged solely by the effect they may or may not have on short-term economic growth.
Which brings me to a final point about the difference between correlation and causation. People with more disposal income probably spend more money on, e.g., books than people with less money. Buying books doesn’t make you rich, at least not in the short-term, but it’s a good thing to do for its own sake. We shouldn’t think of higher education exclusively on the cost side of the economic equation, as politicians and bureaucrats seem increasingly to be doing, it’s also one of the benefits.
![]()
 independent Gaussian-dsitributed varies as
independent Gaussian-dsitributed varies as  ; the larger the sample, the more accurately the global mean can be known. In the cosmological context this is basically why mapping a larger volume of space can lead, for instance, to a more accurate determination of the overall mean density of matter in the Universe.
; the larger the sample, the more accurately the global mean can be known. In the cosmological context this is basically why mapping a larger volume of space can lead, for instance, to a more accurate determination of the overall mean density of matter in the Universe. and
and  each of which has a Gaussian distribution with zero mean and unit variance. The ratio
each of which has a Gaussian distribution with zero mean and unit variance. The ratio 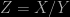 has a
has a  ,
, has the normal form, but this is also true (for large enough
has the normal form, but this is also true (for large enough  doesn’t tend to a Gaussian. In fact the distribution of the sum of any number of independent Cauchy variates is itself a Cauchy distribution. Moreover the distribution of the mean of a sample of size
doesn’t tend to a Gaussian. In fact the distribution of the sum of any number of independent Cauchy variates is itself a Cauchy distribution. Moreover the distribution of the mean of a sample of size 


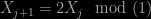
 The critical importance of dealing rationally with uncertainty in science, both within itself and in its relationship to society at large, was the principal issue I addressed in
The critical importance of dealing rationally with uncertainty in science, both within itself and in its relationship to society at large, was the principal issue I addressed in 
