There’s an article in today’s Observer marking the 50th anniversary of the publication of Thomas Kuhn’s book The Structure of Scientific Revolutions. John Naughton, who wrote the piece, claims that this book “changed the way we look at science”. I don’t agree with this view at all, actually. There’s little in Kuhn’s book that isn’t implicit in the writings of Karl Popper and little in Popper’s work that isn’t implicit in the work of a far more important figure in the development of the philosophy of science, David Hume. The key point about all these authors is that they failed to understand the central role played by probability and inductive logic in scientific research. In the following I’ll try to explain how I think it all went wrong. It might help the uninitiated to read an earlier post of mine about the Bayesian interpretation of probability.
It is ironic that the pioneers of probability theory and its application to scientific research, principally Laplace, unquestionably adopted a Bayesian rather than frequentist interpretation for his probabilities. Frequentism arose during the nineteenth century and held sway until relatively recently. I recall giving a conference talk about Bayesian reasoning only to be heckled by the audience with comments about “new-fangled, trendy Bayesian methods”. Nothing could have been less apt. Probability theory pre-dates the rise of sampling theory and all the other frequentist-inspired techniques that many modern-day statisticians like to employ.
Most disturbing of all is the influence that frequentist and other non-Bayesian views of probability have had upon the development of a philosophy of science, which I believe has a strong element of inverse reasoning or inductivism in it. The argument about whether there is a role for this type of thought in science goes back at least as far as Roger Bacon who lived in the 13th Century. Much later the brilliant Scottish empiricist philosopher and enlightenment figure David Hume argued strongly against induction. Most modern anti-inductivists can be traced back to this source. Pierre Duhem has argued that theory and experiment never meet face-to-face because in reality there are hosts of auxiliary assumptions involved in making this comparison. This is nowadays called the Quine-Duhem thesis.
Actually, for a Bayesian this doesn’t pose a logical difficulty at all. All one has to do is set up prior probability distributions for the required parameters, calculate their posterior probabilities and then integrate over those that aren’t related to measurements. This is just an expanded version of the idea of marginalization, explained here.
Rudolf Carnap, a logical positivist, attempted to construct a complete theory of inductive reasoning which bears some relationship to Bayesian thought, but he failed to apply Bayes’ theorem in the correct way. Carnap distinguished between two types or probabilities – logical and factual. Bayesians don’t – and I don’t – think this is necessary. The Bayesian definition seems to me to be quite coherent on its own.
Other philosophers of science reject the notion that inductive reasoning has any epistemological value at all. This anti-inductivist stance, often somewhat misleadingly called deductivist (irrationalist would be a better description) is evident in the thinking of three of the most influential philosophers of science of the last century: Karl Popper, Thomas Kuhn and, most recently, Paul Feyerabend. Regardless of the ferocity of their arguments with each other, these have in common that at the core of their systems of thought likes the rejection of all forms of inductive reasoning. The line of thought that ended in this intellectual cul-de-sac began, as I stated above, with the work of the Scottish empiricist philosopher David Hume. For a thorough analysis of the anti-inductivists mentioned above and their obvious debt to Hume, see David Stove’s book Popper and After: Four Modern Irrationalists. I will just make a few inflammatory remarks here.
Karl Popper really began the modern era of science philosophy with his Logik der Forschung, which was published in 1934. There isn’t really much about (Bayesian) probability theory in this book, which is strange for a work which claims to be about the logic of science. Popper also managed to, on the one hand, accept probability theory (in its frequentist form), but on the other, to reject induction. I find it therefore very hard to make sense of his work at all. It is also clear that, at least outside Britain, Popper is not really taken seriously by many people as a philosopher. Inside Britain it is very different and I’m not at all sure I understand why. Nevertheless, in my experience, most working physicists seem to subscribe to some version of Popper’s basic philosophy.
Among the things Popper has claimed is that all observations are “theory-laden” and that “sense-data, untheoretical items of observation, simply do not exist”. I don’t think it is possible to defend this view, unless one asserts that numbers do not exist. Data are numbers. They can be incorporated in the form of propositions about parameters in any theoretical framework we like. It is of course true that the possibility space is theory-laden. It is a space of theories, after all. Theory does suggest what kinds of experiment should be done and what data is likely to be useful. But data can be used to update probabilities of anything.
Popper has also insisted that science is deductive rather than inductive. Part of this claim is just a semantic confusion. It is necessary at some point to deduce what the measurable consequences of a theory might be before one does any experiments, but that doesn’t mean the whole process of science is deductive. He does, however, reject the basic application of inductive reasoning in updating probabilities in the light of measured data; he asserts that no theory ever becomes more probable when evidence is found in its favour. Every scientific theory begins infinitely improbable, and is doomed to remain so.
Now there is a grain of truth in this, or can be if the space of possibilities is infinite. Standard methods for assigning priors often spread the unit total probability over an infinite space, leading to a prior probability which is formally zero. This is the problem of improper priors. But this is not a killer blow to Bayesianism. Even if the prior is not strictly normalizable, the posterior probability can be. In any case, given sufficient relevant data the cycle of experiment-measurement-update of probability assignment usually soon leaves the prior far behind. Data usually count in the end.
The idea by which Popper is best known is the dogma of falsification. According to this doctrine, a hypothesis is only said to be scientific if it is capable of being proved false. In real science certain “falsehood” and certain “truth” are almost never achieved. Theories are simply more probable or less probable than the alternatives on the market. The idea that experimental scientists struggle through their entire life simply to prove theorists wrong is a very strange one, although I definitely know some experimentalists who chase theories like lions chase gazelles. To a Bayesian, the right criterion is not falsifiability but testability, the ability of the theory to be rendered more or less probable using further data. Nevertheless, scientific theories generally do have untestable components. Any theory has its interpretation, which is the untestable baggage that we need to supply to make it comprehensible to us. But whatever can be tested can be scientific.
Popper’s work on the philosophical ideas that ultimately led to falsificationism began in Vienna, but the approach subsequently gained enormous popularity in western Europe. The American Thomas Kuhn later took up the anti-inductivist baton in his book The Structure of Scientific Revolutions. Initially a physicist, Kuhn undoubtedly became a first-rate historian of science and this book contains many perceptive analyses of episodes in the development of physics. His view of scientific progress is cyclic. It begins with a mass of confused observations and controversial theories, moves into a quiescent phase when one theory has triumphed over the others, and lapses into chaos again when the further testing exposes anomalies in the favoured theory. Kuhn adopted the word paradigm to describe the model that rules during the middle stage,
The history of science is littered with examples of this process, which is why so many scientists find Kuhn’s account in good accord with their experience. But there is a problem when attempts are made to fuse this historical observation into a philosophy based on anti-inductivism. Kuhn claims that we “have to relinquish the notion that changes of paradigm carry scientists ..closer and closer to the truth.” Einstein’s theory of relativity provides a closer fit to a wider range of observations than Newtonian mechanics, but in Kuhn’s view this success counts for nothing.
Paul Feyerabend has extended this anti-inductivist streak to its logical (though irrational) extreme. His approach has been dubbed “epistemological anarchism”, and it is clear that he believed that all theories are equally wrong. He is on record as stating that normal science is a fairytale, and that equal time and resources should be spent on “astrology, acupuncture and witchcraft”. He also categorised science alongside “religion, prostitution, and so on”. His thesis is basically that science is just one of many possible internally consistent views of the world, and that the choice between which of these views to adopt can only be made on socio-political grounds.
Feyerabend’s views could only have flourished in a society deeply disillusioned with science. Of course, many bad things have been done in science’s name, and many social institutions are deeply flawed. One can’t expect anything operated by people to run perfectly. It’s also quite reasonable to argue on ethical grounds which bits of science should be funded and which should not. But the bottom line is that science does have a firm methodological basis which distinguishes it from pseudo-science, the occult and new age silliness. Science is distinguished from other belief-systems by its rigorous application of inductive reasoning and its willingness to subject itself to experimental test. Not all science is done properly, of course, and bad science is as bad as anything.
The Bayesian interpretation of probability leads to a philosophy of science which is essentially epistemological rather than ontological. Probabilities are not “out there” in external reality, but in our minds, representing our imperfect knowledge and understanding. Scientific theories are not absolute truths. Our knowledge of reality is never certain, but we are able to reason consistently about which of our theories provides the best available description of what is known at any given time. If that description fails when more data are gathered, we move on, introducing new elements or abandoning the theory for an alternative. This process could go on forever. There may never be a “final” theory, and scientific truths are consequently far from absolute, but that doesn’t mean that there is no progress.
Follow @telescoper



 observations labelled
observations labelled  . Assume that these are independent and identically distributed with a distribution function
. Assume that these are independent and identically distributed with a distribution function  , i.e.
, i.e.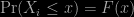
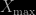 . What is the distribution of this value? The answer is not
. What is the distribution of this value? The answer is not  is just the probability that each one is less than or equal to that value, i.e.
is just the probability that each one is less than or equal to that value, i.e.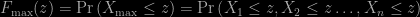
![F_{\rm max} (z) = \left[ F(z) \right]^n](https://s0.wp.com/latex.php?latex=F_%7B%5Crm+max%7D+%28z%29+%3D+%5Cleft%5B+F%28z%29+%5Cright%5D%5En&bg=000000&fg=B0B0B0&s=0&c=20201002)
![f_{\rm max}(z) = n f(z) \left[ F(z) \right]^{n-1}](https://s0.wp.com/latex.php?latex=f_%7B%5Crm+max%7D%28z%29+%3D+n+f%28z%29+%5Cleft%5B+F%28z%29+%5Cright%5D%5E%7Bn-1%7D&bg=000000&fg=B0B0B0&s=0&c=20201002)
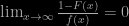
 which is independent of the underlying distribution,
which is independent of the underlying distribution, 
 and
and  are location and scale parameters; this is called the
are location and scale parameters; this is called the  !
! ! This is why I advocate using the exact distribution resulting from a fully specified model whenever this is possible.
! This is why I advocate using the exact distribution resulting from a fully specified model whenever this is possible.

